
Compute Server
As noted earlier, Gurobi Compute Server is an optional component of Gurobi Remote Services that allows you to choose one or more servers to run your Gurobi computations. You can then offload the work associated with solving optimization problems onto these servers from as many client machines as you like:
When considering a program that uses Gurobi Compute Server, you can think of the optimization as being split into two parts: the client and the compute server. A client program builds an optimization model using any of the standard Gurobi interfaces (C, C++, Java, .NET, Python, MATLAB, R). This happens in the left box of this figure:
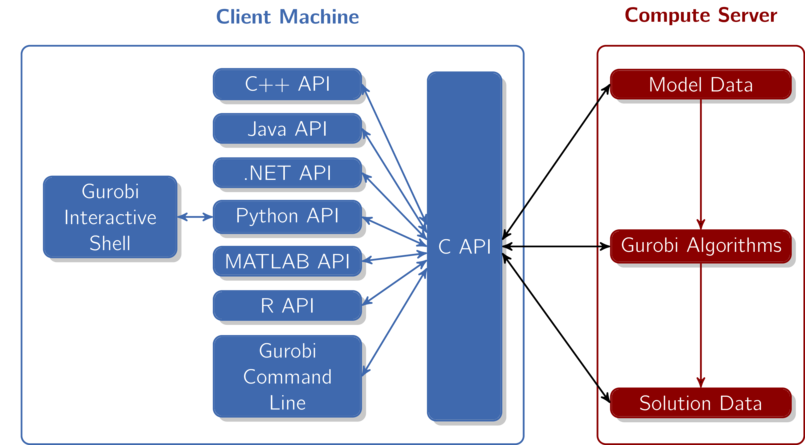
All of our API's sit on top of our C API. The C API is in charge of building the internal model data structures, invoking the Gurobi algorithms, retrieving solution information, etc. When running Gurobi on a single machine, the C API would build the necessary data structures in memory. The Gurobi algorithms would take the data stored in these data structures as input, and produce solution data as output.
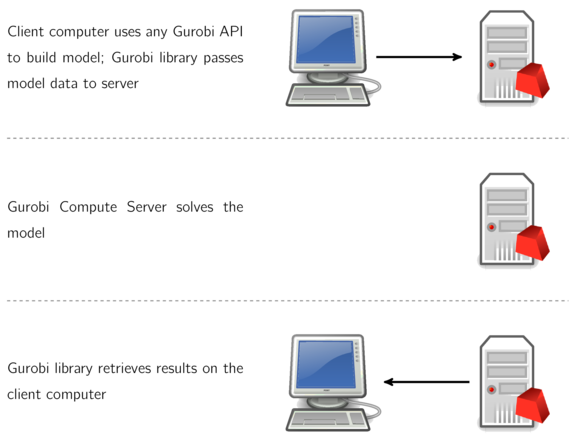
When using a Compute Server, the C API instead passes model data to the server, where it is stored. When the Gurobi algorithms are invoked, the C API simply passes a message to the server, indicating that optimization should be performed on the stored model data. Solution data is computed and stored on the server. When the client program later queries the solution information, the client sends a message to the server in order to obtain the requested data. All communication between the client and server happens behind the scenes,
In other words, the overall process can be viewed as happening in three phases:
Gurobi Compute Servers support queuing and load balancing. You can set a limit on the number of simultaneous jobs each Compute Server will run. When this limit has been reached, subsequent jobs will be queued. If you have multiple Compute Server nodes configured in a cluster, the current job load is automatically balanced among the available servers.
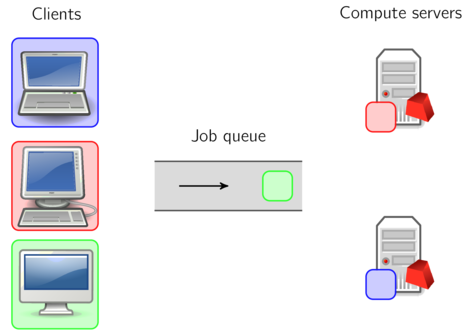
By default, the Gurobi job queue is serviced in a First-In, First-Out (FIFO) fashion. However, jobs can be given different priorities (through a client license file, or through API calls). Jobs with higher priorities are then selected from the queue before jobs with lower priorities.
While the Gurobi Compute Server is meant to be transparent to both developers and users, there are a few aspects of Compute Server usage that you do need to be aware of. These include performance considerations, APIs for configuring client programs, and a few features that are not supported for Compute Server applications. These topics will be discussed later in this document.








