

本記事はGurobi.comに掲載されている下記の記事を日本語訳しています。
著者:Dr. Cara Touretzky、Dr. Robert Luce、Dr. David Torres Sanchez
ハードウェアとアルゴリズムの選択肢
モデリング(The art of modeling)に集中したい私たちにとって、異なるハードウェアオプションが最適化のパフォーマンスに与える影響は容易に理解できます。そして、Gurobi のような信頼性の高いソルバーがあれば、モデラーは内部でデプロイされているアルゴリズムについて考える必要はありません。
しかし、ハードウェアの選択肢は進化し続けており、最適化分野で使用されるアルゴリズムも同様に進化しています。LP を解くための単体法とバリア法(内点法)は確立されており(そして毎年改善され続けています)、主双対ハイブリッド勾配法(Primal-Dual Hybrid Gradient method: PDHG、特に線形計画法向けに強化・適応された場合は PDLP とも呼ばれます)は、GPU ベースの実装に適しているため、最近大きな注目を集めています。
新しい GPU 対応アルゴリズムであるバリア法と PDHG の登場で、一般の最適化ユーザーは、最適化モデルをデプロイする際にハードウェアとアルゴリズムの選択が与える影響を理解することで新しい利益を得られます。特に、最速の求解時間をもたらすハードウェアとアルゴリズムの組合せを見つけたい場合にはそれが顕著です。
注意:ハードウェアとアルゴリズムの選択に関して万能の処方はありません。「モデルに依存する」という古典的なアドバイスは依然として当てはまります。今回 Gurobi では、アルゴリズムとハードウェアオプションを徹底的に比較しました。私たちは、これらの選択肢をナビゲートするのに役立つよう、私たちのアプローチと業界で実証されたベンチマーク結果を最適化コミュニティと共有したいと考えています。
この記事は、GPU へ適用可能なアルゴリズムを解き明かし、最適化の分野における新たな機会を明らかにします。具体的には、巨大な LP(および巨大な LP 緩和に依存する MIP)が、GPU 対応のLP アルゴリズムから顕著な速度向上を期待できる有望な分野であることを観察しています。
Gurobi は、最適化分野の新しいイノベーションを産業アプリケーション向けの実用的なツールに変えてきた実績があります。これまで、これはソルバーの能力の最前線を押し広げている Gurobi のお客様との密接な協力によって達成されてきました。Gurobi が様々なハードウェアとアルゴリズムの選択肢を比較するためのベンチマーク手法を確立した今、私たちは皆様の現実世界のモデルをテストする準備ができています。GPU アクセラレーションされたソルバーでモデルのパフォーマンスをテストすることにご興味があれば、「Gurobiのサポートを受けるにはどうすればよいですか?」からお問い合わせください。
最適化とGPU空間の世界を解き明かす
私たちは、新しいハードウェアとアルゴリズムのオプションを組み合わせて、巨大な LP を解くための複数のセットアップを調査しました。
調査したハードウェア選択肢:
CPU 1: Grace Hopper Superchip 200(GH200)の CPU (72 コア)
CPU 2: AMD の EPYC 9655(96 コア)
GPU: GH200 チップの GPU
CPU オプションについては、すべてのベンチマークは利用可能な合計コア数ではなく、64 コアを使用して実行されています。いずれのマシンでも 64 コア以上を使用して得られるメリットは少なく、すべてのテストで同じ数のコアを使用することで単純な比較が可能になりました。
巨大なLPに対するGurobiのアルゴリズム選択肢:
巨大な LP のための Gurobi のアルゴリズムオプションは、(1)バリア法、および(2)PDHG(一次法)です。これら 2 つのアルゴリズムは、計算の方式が大きく異なります。最も重要な特性をまとめます。
バリア法の場合、各イテレーションでの最も重い計算ステップは、大規模で疎な連立一次方程式系の求解です。GPU では、この操作を実行するために NVIDIA の cuDSS ライブラリを使用しており、CPU では、標準の自社製マルチスレッドアルゴリズムを使用しています。
PDHG では、イテレーションごとの最も重要なアルゴリズム操作は、疎行列(またはその転置)と密ベクトルとの乗算です。GPU では、この操作を実行し、すべてのデータを GPU メモリに常駐させるために NVIDIA の cuSPARSE ライブラリを使用しており、高価なメモリ転送は不要です。CPU では、このような行列ベクトル積は、標準の自社製マルチスレッドアルゴリズムを使用して計算されます。
なぜ主双対単体法がこの議論に含まれていないのか疑問に思われるかもしれませんが、それらのアルゴリズムは CPU ハードウェア上で並列化が困難であり、GPU 上ではさらに困難であるためです。
収束トレランスとクロスオーバー
主要な LP アルゴリズムの収束動作はそれぞれ異なります。バリア法は局所的に二次収束を示すという利点があるため、解に近づくと、残差を小さな値まで非常に迅速に縮小できます。一方、PDHG は最良でも線形収束を示すため、非常に小さなトレランスに到達するのに時間がかかる場合があります。
収束を定義するために使用するトレランスは変わることがありますが、業界慣行では一般的に 1e-6 未満の残差が品質の高い解として受け入れられることに同意しているようです。可能な限り迅速に解を得ようとする際に収束トレランスを増加させるリスクは何でしょうか?その質問に答えるために、クロスオーバーとそれがバリアと PDHG アルゴリズムの結果を改善するために追加の時間を必要とすることについて話す必要があります。
クロスオーバー(CrossOver)は、LP に非シンプレックス法を使用する際に必要な重要でありながらしばしば忘れられるステップです。要約すると、クロスオーバーは LP 解を「クリーンな基底解」に変換するのに役立ちます。バリア法(または一次法)からの解は通常、ゼロに近いノイズの多い値を持ち、さらに重要なことに、これらのために様々な指標(主実行可能性、双対実行可能性、相補スラック性など)で違反を持つ可能性があります。クロスオーバーはこれらの違反をクリーンアップし、クリーンで疎な基底解を提供するのに非常に効果的です。
私たちのお客様のほとんどは、基底解を解釈可能性に不可欠なものと考えています。したがって、これらの新しいアルゴリズムを評価する際、クロスオーバーを完了するのに必要な時間も考慮する必要があると感じています。以下の結果でこの重要性がさらに明確になるでしょう。一部のアルゴリズムでは、精度とクロスオーバーを完了するのに必要な時間の間に明確なトレードオフがあるからです。
ベンチマーク結果
もちろん、「最良」または「最速」のマシンがすべての最適化問題を等しく高速に解決することを期待したいところです。しかし実際には、上記で言及した異なるハードウェア選択肢と2つのアルゴリズム間で大きな変動を観察することができます。
MIPLIBモデルの公開ライブラリから 2 つの洞察に富む例を示し、私たちの内部ベンチマークセットからの結果についてのコメントで結論づけます。MIPLIB の例は、モデル、アルゴリズム、ハードウェア選択の組合せによる解時間の可能な変動を示すため選択されました。これらの結果のより詳細な分析については、New Options for Solving Giant LPs – Gurobi Optimization をご覧ください。
実験から得られた主要な発見:
GPU は通常、PDHG とバリア反復を CPU よりもはるかに高速に実行しますが、それが必ずしも実行時間の大幅な短縮に直接つながるわけではありません。
CPU 上でも、一部のモデルでは PDHG が最適なアルゴリズムとなる場合があります。
CPU 上でも、バリアが最適なアルゴリズムとなるケースは依然として存在します。GPU でバリアを実行することで大幅な改善が得られる可能性がありますが、PDHG ほど一貫性はありません。
収束トレランスを大きくすると、特に PDHG では処理速度が向上しますが、クロスオーバーが高品質な解を得るための総時間の大部分を占める可能性があります。これは実践的なトレードオフです。
例モデル1:rwth-timetable
最初のモデル(「rwth-timetable」)は、バリアアルゴリズムで膨大な計算量を必要とする多くの行と列を持つ時間割問題の LP 緩和問題です。統計情報は以下の通りです:
rwth-timetable: 440,134 行、923,564 列、4,510,786 非ゼロ要素
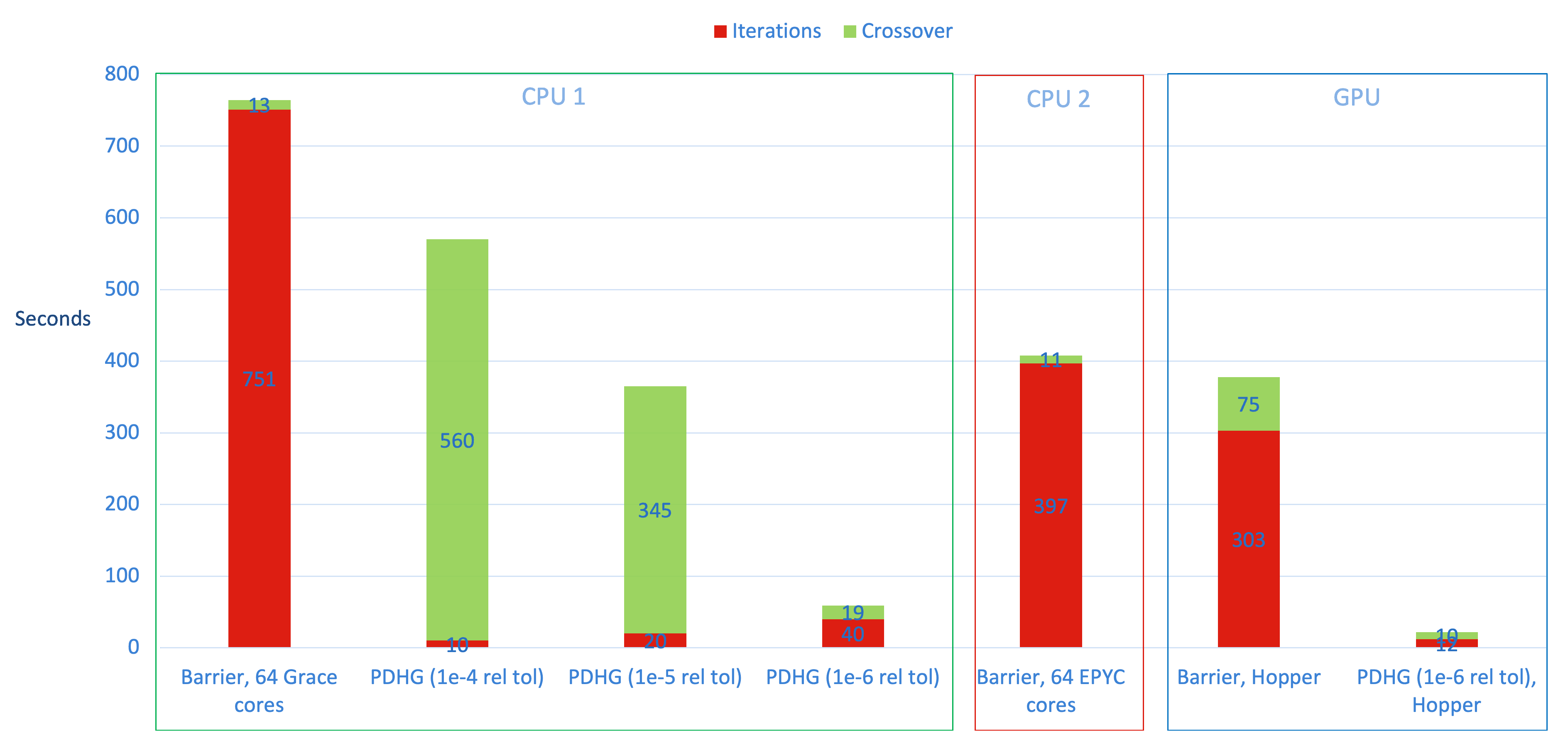
異なるハードウェアとアルゴリズム選択肢の比較を棒グラフで視覚化します。各棒は異なるハードウェアとアルゴリズムの組合せに対応し、PDHG には異なる終了基準(トレランス)を持つ複数の列があることに注意してください。各棒は 2 つの色に分かれています:各アルゴリズムで反復を実行するのに費やした時間(赤)、クロスオーバーに費やした時間(緑)。
この最初の例では、小さな収束トレランス(1e-6)を持つPDHGが、ハードウェア(CPU 1またはGPU)に関係なく明確な勝者であることがわかります。最後の 2 つの棒で示されるように、GPUで実行される両方のアルゴリズムはCPU対応部分に対して何らかの改善をもたらします。具体的には、GPUでのPDHGについて、CPU 1に対して 62.71% の改善を見てとれます。GPUでのバリア法については、CPU 1 に対して50%の改善、CPU 2 に対してはわずかに 7% の改善を確認できます。
もう一つの興味深い発見は、予想通り、より大きなトレランスを持つ PDHG は反復実行により少ない時間を費やすことですが、残念ながらこれは総求解時間の短縮には役立ちません。代わりにクロスオーバーが求解時間の大部分を占めるからです。これは、クロスオーバーが高品質の LP 解から大きな恩恵を得るためです。
例モデル2:rmine25
2番目の問題は、膨大な数の行を持つ露天掘り問題(「rmine25」)の LP 緩和問題です:
rmine25: 2,953,849 行、326,599 列、7,182,744 非ゼロ要素
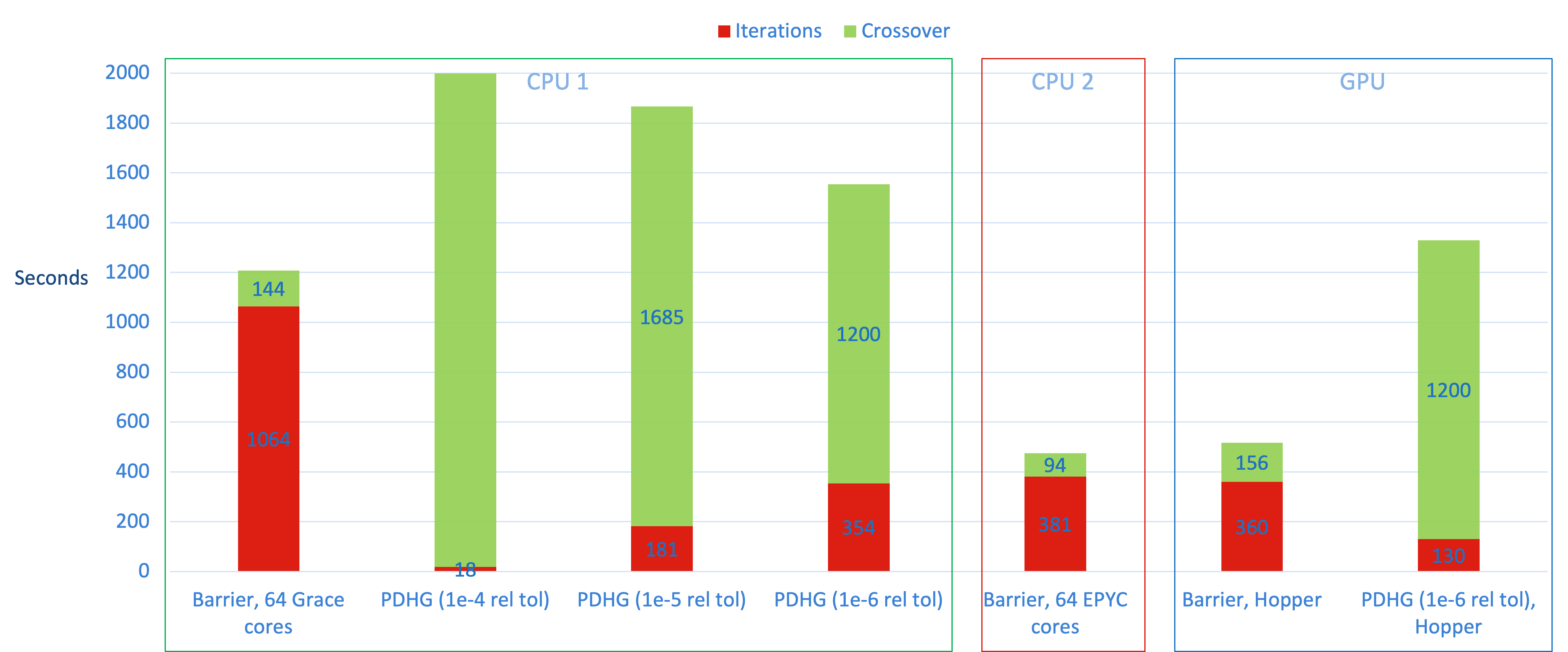
rmine25の結果では、すべてのハードウェア選択肢においてバリア法が最適なアルゴリズムであり、最速の CPU 2 を使用する場合にさらなる利点があることがわかります。バリアの CPU 2 と GPU バージョンの両方が CPU 1 に対してほぼ 40% の速度向上を示します。興味深いことに、収束トレランスが 1e-6 と小さくてもクロスオーバーに費やされる時間が PDHG 実行時間を支配しています
結論
今回の実験結果では、どのアルゴリズムとハードウェアの組合せが与えられたモデルにとって最適であるかを予測することは困難であり、終了トレランスがクロスオーバーに与える影響については言うまでもありません。言い換えれば、万能の組合せが存在しないと言っても過言ではありません。そして、私たちはこの議論に他の興味深い現象の範囲を考慮に入れていません。例えば、これらの 2 つのモデルでは CPU 2 と GPU のバリア法の実行時間は大きく比較可能ですが、cuDSS が行っている因数分解のスループットは、CPU で達成するスループットよりもはるかに大きい場合があることを確認しています。
研究は続く
ハードウェアの選択肢についてさらに学びたかった「最適化に携わる人」であろうと、最適化についてさらに学びたかった「高性能計算に携わる人」であろうと、この記事が GPU 対応の最適化アルゴリズム分野の最新の取り組みへの理解を深めるのに役立ったことを願っています。
先に述べたように、最適化におけるハードウェアとアルゴリズムの選択に関して万能の処方はありません。私たちは、すべてのモデルを、どの組合せが最適かをテストする必要がある独立な作成物として扱うことを依然として推奨します。前述の 2 つの例は、現在利用可能な最先端のハードウェアオプションを考慮した場合に、これらの選択肢が与えうる影響を反映しています。
ハードウェアおよび関連ライブラリ(GPU 対応アルゴリズムに NVIDIA の cuDSS および cuSparse ライブラリを利用したことを思い出してください)は継続的に進化しているため、ベンチマークの結果は急速に変化すると予想しており、将来的にバリア法と PDHG が GPU 上でさらに多くのユースケースで利益をもたらす可能性も十分にあります。
この時点で、Gurobi には多くの現実世界のケーススタディがあるのに、なぜ MIPLIB データベースのモデルの結果しか共有していないのか疑問に思われるかもしれません。私たちの予備的および内部ベンチマークでは、PDHG がデフォルト設定よりも優れているモデルは 2633 モデル中わずか 72 モデル(そのうち 17 モデルだけが 2 倍以上の改善を示しています)にすぎません。しかし、私たちのコレクションの性質上、このセットは単体法または IPMs のいずれかで既に解ける LP に大きく偏っています。私たちのテストセットに、解けない巨大な LP が含まれていないのはなぜでしょうか?これはより哲学的な問題です。なぜなら、現在のソルバー技術では扱えないと予想されるのに、なぜ誰かが巨大な LP を書くのでしょうか?
これは活発な研究分野であり、「巨大」という認識は常に変化しています。新しい GPU 対応アルゴリズムについて、私たちの最初の印象は、人々がまだ構築することをチャレンジしていないほど巨大なモデルに最大の利益をもたらすだろうということです。もちろん、「巨大」ではないが、新しいアルゴリズムと GPU ハードウェアの使用を正当化するレベルの複雑さと重い計算ニーズを持つモデルも探索しています。
GPU アクセラレーション最適化でモデルを最適化することにご興味がありますか?「Gurobiの使用に関するサポートを受けるには?」からお問い合わせください。
最適な評価ライセンスを選択し、技術トランスファーとサポートのために我々のエキスパートチームとの作業を開始してください。無料試用ライセンスをリクエストして、クラウド上でモデルがどれほど迅速かつ簡単に解決できるかをご確認ください。
